We need POSIX for MLOps
If you work on MLOps, you must navigate an ever-growing landscape of tools and solutions. This is both an intense source of stimulation and fatigue for MLOps practitioners.

Vendors and users face the same problem: How can we combine all these tools without the combinatorial complexity of creating custom integrations?
import math
# number of AI/ML tools -> number of possible integrations
print({n: math.comb(n, 2) for n in range(10, 100+10, 10)})
{10: 45, 20: 190, 30: 435, 40: 780, 50: 1225, 60: 1770,
70: 2415, 80: 3160, 90: 4005, 100: 4950}In this article, I propose a solution analogous to POSIX to address this challenge. First, I motivate the creation of common protocols and schemas for combining MLOps tools. Second, I present a high-level architecture to support implementation. Third, I conclude with the benefits and limitations of standardizing MLOps.
What is POSIX?
POSIX (Portable Operating System Interface) is a set of standards specified by the IEEE for defining a level of compatibility between operating systems (e.g., Linux, MacOS, BSD, …).
More concretely, POSIX is the foundation that allows end users to implement new applications and ensure they can communicate with each other. This can be done with shell commands (e.g., ls, df, pwd, …) and pipelines (e.g., fd | sort | unique), or with more complex interfaces such as network sockets.
POSIX is also linked with the Unix Philosophy, an approach that favors composability over monolithic design. To quote Doug McIlroy (1978):
- Make each program do one thing well. To do a new job, build afresh rather than complicate old programs by adding new “features”.
- Expect the output of every program to become the input to another, as a yet unknown, program. Don’t clutter the output with extraneous information. Avoid stringently columnar or binary input formats. Don’t insist on interactive input.
- Design and build software, even operating systems, to be tried early, ideally within weeks. Don’t hesitate to throw away the clumsy parts and rebuild them.
- Use tools in preference to unskilled help to lighten a programming task, even if you have to detour to build the tools and expect to throw some of them out after you’ve finished using them.
Why do we need POSIX for MLOps?
As ML Engineers we have 2 possibilities for implementing an AI/ML solution: either go all-in on a set of tools or create interfaces to combine, remove, and replace tools that are part of the solution.
Going all-in is often the easier way to go. For instance, we can start a new project with MLflow for experiment tracking, TensorFlow as our ML framework, and Great Expectations to validate our data. But wait, now the team wants to switch to Neptune, PyTorch Lightning, and Evidently … That's a lot of rewrite and rework!
Our goal as an engineer is to create abstractions and protocols to avoid such hassle. On the web, we can use any web browser (e.g., Chrome, Firefox, Edge), with any web server (e.g., NGINX, Apache, Gunicorn) without any rewrite or custom integration. If something wants to create a new web program, this entity can do it without asking for permission or requiring changes from other actors.
AI/ML is a complex field where new solutions are constantly added to solve an increasing number of user cases. We should not limit nor slow the growth of AI/ML because of inconvenient software design.
How should we implement it?
My proposal is to massively leverage message brokers like Apache Kafka, Redis, or ZeroMQ to exchange metadata and instructions between AI/ML components. The main benefit of message brokers is to minimize the mutual awareness between components and decouple information sharing between producers and consumers. As Rich Hickey explained, this kind of architecture supports the emergence of a Language of the System. This is also the paradigm behind the design of the Erlang language.
For MLOps, this means separating each component such as Experiment Tracker, Model Training, or Pipeline Monitoring (e.g., using Python module or Docker container), and exchanging information only through message brokers. This design seeks to implement the SOLID principles:
- Single-responsibility principle: “There should never be more than one reason for a class to change.”
- The Open–closed principle: “Software entities should be open for extension, but closed for modification.”
- The Liskov substitution principle: “Functions that use pointers or references to base classes must be able to use objects of derived classes without knowing it.”
- The Interface segregation principle: “Clients should not be forced to depend upon interfaces that they do not use.”
- The Dependency inversion principle: “Depend upon abstractions, [not] concretions.”
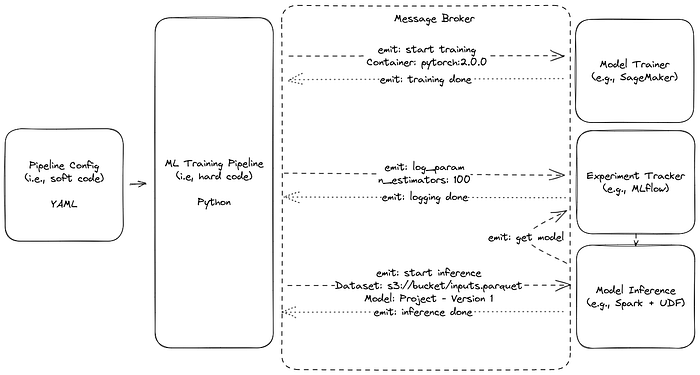
Each MLOps component should work like a micro-service. When the component receives an instruction (e.g., log a parameter, get the location of a model, …), it should reply to the sending process with the information requested. A message can be dispatched to several components (i.e., fan out), and the component can acknowledge that the message has been processed with a status or error message. The components should be as loosely coupled as possible, and they must be configured with a creational pattern to swap the components with soft code (e.g., configuration files).
In addition, common schemas (i.e., names for things) are required to enable global integrations between MLOps tools. The main benefit of POSIX is not only to provide design concepts (e.g., file descriptors), but also standard names to facilitate the collaboration between actors (e.g., /dev/std{in,err,out} for standard streams).
Conclusions
MLOps is a complex field and we should not make this field even more complex through accidental complexity. MLOps actors need to facilitate the interoperability of the tools we build so we can focus on the real problems: deliver value to our organizations. The high-level architecture proposed in this article is an attempt to answer this problem through common protocols and standard naming.
However, there is a hard truth I acknowledge: nobody got rich or famous from creating a standard. While this contribution would be beneficial for all MLOps actors, no individual has the incentive to create this initiative on its own. The alternative is to wait for Darwinism to cull the MLOps tools available, but I'm not sure the best solutions will emerge from this process.
Finally, there is also another thing you need to know about standards. But I think XKCD does a better job than me at explaining it 😄.

