Stop Building Rigid AI/ML Pipelines: Embrace Reusable Components for Flexible MLOps
Let’s be honest, we’ve all been there. You start an MLOps project with the best intentions: crafting a beautiful pipeline that combines several steps. Data ingestion, preprocessing, model training, evaluation, deployment — it all flows seamlessly. At first. But then, reality hits. A new data source emerges. You need to experiment with different preprocessing techniques. Some steps must be reused across several projects. Suddenly, your elegant monolithic pipeline resembles a tangled mess of spaghetti code, complecting what should be executed (the code) and how it should be executed (the pipeline).
The problem? Traditional, monolithic MLOps pipelines are inherently rigid. They couple your individual MLOps steps tightly, making them difficult to modify, reuse, or even understand in the long run. This inflexibility slows down iteration, hinders experimentation, and ultimately, increases the risk of your AI/ML project.
The Solution: Reusable Artifacts and DAGs
What if, instead of a rigid pipeline, we could build our MLOps projects from modular, reusable building blocks? This is where the concept of artifact-driven MLOps comes in.
Think of it like this: Instead of baking a single, giant cake (your pipeline), you’re now in a professional kitchen, preparing individual ingredients (your reusable artifacts). You have your perfectly sifted flour (data preprocessing), your expertly tempered chocolate (model training), and your precisely whipped cream (model evaluation). Each ingredient is prepared separately, stored in its own container, and ready to be combined in various ways.
Breaking Down the Artifact-Driven Approach

The core idea is to encapsulate each step of your MLOps process into independent, reusable artifacts. These artifacts typically take the form of:
- Python Packages: Containing core logic for tasks like data preprocessing, feature engineering, or model training, where a package is divided into jobs and exposed through entrypoint (e.g., project scripts).
- Docker Images: Providing isolated, reproducible environments for running your code, packaged with their dependencies in a Dockerfile.
- Config Files: Controlling the behavior of your code without requiring code changes (e.g., model hyperparameters, input/output files, …).

These artifacts are stored in a code repository like GitHub and built by a CI/CD like GitHub Actions on release. Here’s how it looks in practice:
- Modularize Your Codebase: Each Python package contains logically grouped code, exposes functions, classes, or even CLI commands via entry points, and has its own dependencies.
- Build and Version Artifacts: Use CI/CD pipelines to automatically build, test, and version your Python packages and Docker images upon code changes.
From Artifacts to Action: Orchestration with DAGs

Now that we have our reusable artifacts, how do we combine them into a meaningful workflow? This is where Directed Acyclic Graphs (DAGs) come into play. A DAG, often managed by orchestration tools like Apache Airflow, Dagster, and Prefect, allows you to define a workflow as a series of interconnected tasks, each loading and executing artifacts.
Visualize the Power of DAGs:
Let’s look how we can assemble our artifacts into distinct workflows.
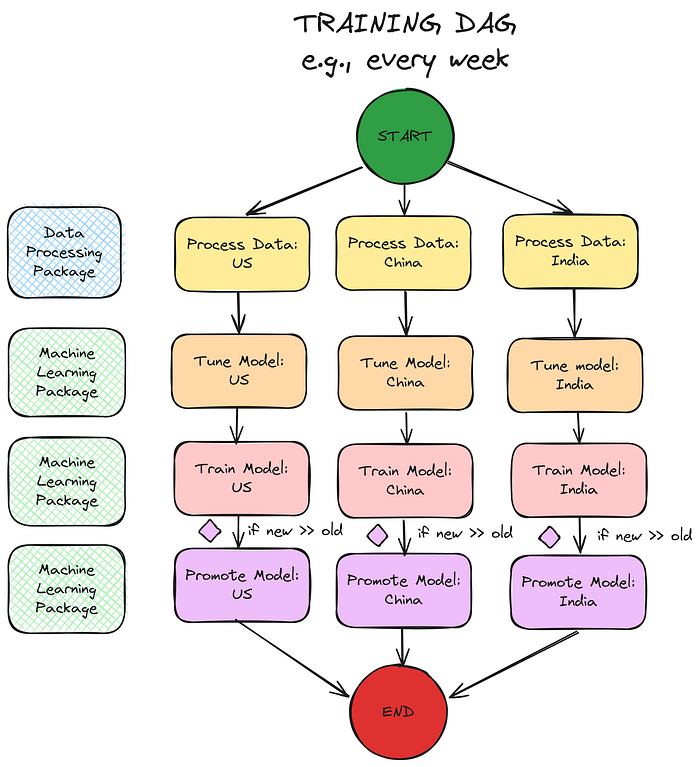
The training DAG will prepare the data (yellow squares), tune/train the model (orange and red squares), and promote the model (purple squares) if the new model outperforms the previous version. The DAG can parallelize the step execution (e.g., by country or product category) to improve performance, and adapt the resources allocated to each step (e.g., big countries get more powerful compute instances).
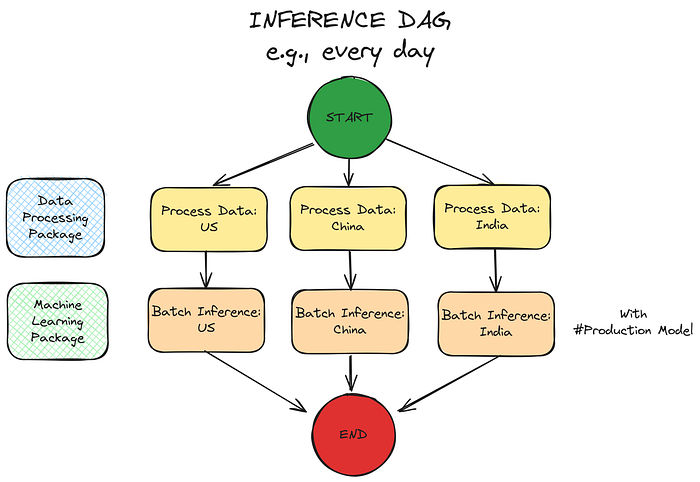
The Inference DAG can use the same software artifacts as training DAG. In this case, the data processing package is reusing to process data, and the machine learning package can generate predictions through batch inference. As input, this step takes the production model stored in a model registry like MLflow.
Notice the advantages of this approach:
- Flexibility: You can easily swap out components. Need to experiment with a different preprocessing technique? Simply create a new artifact and plug it into the DAG. You don’t need to repeat the data transformation and preparation in the Inference DAG, since it is the same as the Training DAG.
- Reusability: The same artifact (e.g., a Docker image containing your model training code) can be used in multiple DAGs or even across different projects.
- Extensibility: If you need to handle a new task (e.g., new country or product category, …), you just add a new step in the DAG and provide a configuration file to change the behavior of the code.
Applying Functional Programming Paradigm in MLOps
The artifact-driven approach we’ve been discussing shares a strong conceptual link with functional programming. In functional programming, we strive to build software from pure functions — self-contained units of code that take input and produce output without side effects. These functions are composable, meaning they can be combined in various ways to create more complex behavior.
This is very similar to how we’re using artifacts in MLOps. Each artifact (Python package, Docker image with its entry points, config files) can be viewed as a functional unit. It encapsulates a specific task (the “what”) and is independent of the execution context (the “how”). The DAG then acts as a higher-order function, orchestrating the execution of these functional units in a specific order, defining the overall workflow.
Conclusion: Build for the Future
Embracing reusable artifacts and DAGs is a paradigm shift in MLOps. It’s about moving away from rigid, monolithic pipelines towards a more modular, flexible, and scalable approach. While it may require a slight shift in mindset and tooling, the long-term benefits are undeniable. You’ll be able to iterate faster, experiment more freely, and ultimately, deliver better AI/ML solutions.
So, the next time you start an MLOps project, remember the professional kitchen analogy. Stock your pantry with high-quality artifacts, and use DAGs to orchestrate your culinary (or machine learning) masterpieces.
