Is AI/ML Monitoring just Data Engineering? 🤔
While the future of machine learning and MLOps is being debated, practitioners still need to attend to their machine learning models in production. This is no easy task, as ML engineers must constantly assess the quality of the data that enters and exits their pipelines, and ensure that their models generate the correct predictions. To assist ML engineers with this challenge, several AI/ML monitoring solutions have been developed.
In the past few weeks, I reviewed several of these AI/ML monitoring solutions for a client. We considered vendor solutions (Arize, Superwise, Aporia), open-source solutions (Evidently, Deepchecks), and even building our own solution. These reviews gave me a lot of food for thought about the essence of AI/ML monitoring and how it should fit into an MLOps lifecycle.

In this article, I will discuss the nature of AI/ML monitoring and how it relates to data engineering. First, I will present the similarities between AI/ML monitoring and data engineering. Second, I will enumerate additional features that AI/ML monitoring solutions can provide. Third, I will briefly touch on the topic of AI/ML observability and its relation to AI/ML monitoring. Finally, I will provide my conclusion about the field of AI/ML monitoring and how it should be considered to ensure the success of your AI/ML project.
AI/ML Monitoring is Data Engineering …
There are many similarities between AI/ML monitoring and data engineering. Let’s first look at a simplified AI/ML pipeline in production:

We can spot several common points with a data engineering pipeline:
- Each pipeline step ingests and produces data.
- Steps can be chained together (e.g., like a UNIX pipeline).
- At the end of the process, it produces alerts, metrics, and dashboards.
We can also spot some differences specific to AI/ML pipelines:
- There is an AI/ML model used at some point.
- … and that’s it!
Does the use of an AI/ML model make a big difference in a data pipeline? On the one hand, it is just another step that takes data in and generates data out. On the other hand, AI/ML models require extra attention to properly handle the methodology (e.g., avoiding data leakage), hardware (e.g., using GPUs), and new components (e.g., model registries). As this additional complexity requires a specific set of skills and expertise, I tend to think this difference matters. The best proof is that we need specific engineers to manage these challenges (i.e., ML engineers).
Let’s now explore how this question affects AI/ML monitoring.
… and it is also more than Data Engineering
The added value of AI/ML monitoring can be summarized in one word: semantics. People are much more efficient at dealing with specific concepts than generic ones. To quote this great article from François Chollet (User experience design for APIs):
Like most things, API design is not complicated, it just involves following a few basic rules. They all derive from a founding principle: you should care about your users. All of them. Not just the smart ones, not just the experts. Keep the user in focus at all times. Yes, including those befuddled first-time users with limited context and little patience. Every design decision should be made with the user in mind.
For example, in neural networks, we can use user-friendly concepts such as “layers”, “dropout”, and “pooling” instead of more general terms like “operations”, “filters”, and “aggregations”. Similarly, for AI/ML monitoring, we can adapt the UI and API to deal with concepts like “segments”, “baselines”, and “environments”. The underlying techniques can be found in every data engineering pipeline, but the user experience has been tailored to focus users on their use cases and help them become more productive.
This raises the question of whether this additional semantic value is valuable for data scientists and ML engineers. I believe that it is. Naming things (i.e., coming up with the semantics) is hard, and humans tend to be lazy (i.e., systems 1 and 2). Our main struggle is always to structure the solution and find the best abstractions to empower developers without adding too much complexity. Therefore, it is best to let experts in the field think of the best solutions, just as most web developers do when they use a framework written by specialists in this domain.
Let’s now review how the authors of AI/ML monitoring solutions can help.
My opinion on AI/ML monitoring solutions
All the AI/ML monitoring solutions I tested have nailed the core workflow: data ingestion, metric computation, alert notification, and error visualization. While they all have their strengths and weaknesses, I can see how each of these solutions can bring value to end users and help them get started with better tools and practices.
However, I found a major flaw with most vendor-based solutions: they do not allow metrics to be exported to other systems. This is problematic for two reasons. First, users cannot leverage vendor solutions to support custom use cases (e.g., to expose metrics to the business or optimize the training of their models). This means that ML engineers either have to adopt the vendor’s solution entirely and stick with it, or recreate custom pipelines to meet their other needs. Second, most vendors reimplement existing components instead of leveraging the ones developed by other vendors. For instance, I would rather use Tableau for visualization and Datadog for alerting than the tools provided by AI/ML monitoring vendors. AI/ML monitoring vendors cannot catch up to the years of development and dedication that other data vendors have put into their products.
I do not blame AI/ML monitoring vendors for this. It is challenging to create all of these integrations as there is no common protocol for MLOps systems. We have HTTP, SMTP, and TCP/IP as a universal bridge for the internet, but we do not have anything similar for MLOps. As a result, ML engineers are left with only two options: (1) hope that the vendors will fulfill all of their use cases now and in the future, or (2) build their own solution and focus on the interoperability of their platform. Based on your profile (i.e., end-user vs. engineer), you might choose one over the other.
A note on AI/ML Observability
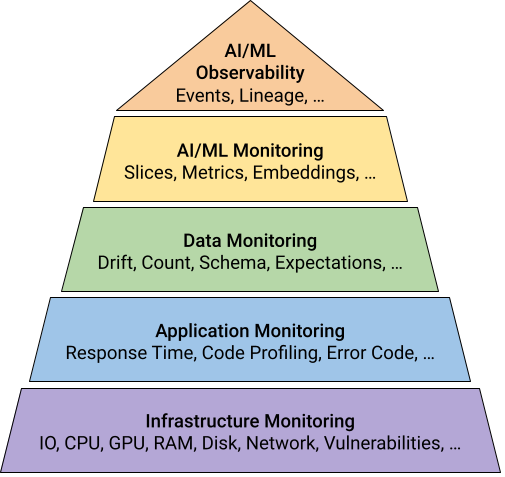
Recently, we had an interesting discussion about AI/ML monitoring and observability in the MLOps community. Raphaël Hoogvliets even wrote a great article that summarizes these concepts. In short, AI/ML monitoring refers to the ability to monitor individual components (e.g., which error occurred, where, and when), while AI/ML observability provides a holistic and high-level overview of the entire system (e.g., why the error occurred and what caused it).
Many AI/ML monitoring vendors advertise themselves as “AI/ML observability solutions.” However, I believe this is overstated, as most of their solutions only look at individual models and consider only their inputs and outputs. They do not monitor the entire data pipeline (e.g., the first dataset used), nor are they able to relate the events that occur during its operation (e.g., a new column was added by another team).
As a result, it is up to the ML engineer to provide these AI/ML observability capabilities across the entire pipeline. ML engineers can use a lineage system (e.g., OpenLineage) or implement an Event-Driven Architecture (EDA) to trace the high-level signals that are triggered throughout the pipeline’s lifetime. Data contracts can also be used to define what is “normal” and what is not. I believe this is a promising area of research that has the potential to improve the maturity of MLOps platforms.
Conclusions
AI/ML monitoring can be seen as a superset of data engineering, but it should not be treated as a subset. In this way, AI/ML monitoring solutions can help bridge the gap between data toolkits and MLOps use cases, as long as they do not remove the ability to integrate their metrics with other systems. While the temptation and constraints to adopt the best solutions on the market can be high, I encourage you to consider whether the value proposition meets both your needs AND your software principles.
To conclude this article, I would like to refer to one of my favorite books: Gödel, Escher, Bach by Douglas R. Hofstadter. I love how the author describes the never-ending loop that arises when systems remain as open as possible, even to themselves. For example, DNA creates proteins that can change or manage DNA, and a program can take instructions to create another program (i.e., a compiler). I find similarities in data and AI/ML pipelines, and I would be fascinated by an MLOps process that could create a model capable of managing MLOps processes. We should strive to focus on the composability and interoperability of our systems, as we never know what may come next.

